Diffusing Gaussian Mixtures for Categorical data
Learning a categorical distribution comes with its own set of challenges. A successful approach taken by state-of-the-art works is to cast the problem in a continuous domain to take advantage of the impressive performance of the generative models for continuous data. Amongst them are the recently emerging diffusion probabilistic models, which have the observed advantage of generating high-quality samples. Recent advances for categorical generative models have focused on log likelihood improvements. In this work, we propose a generative model for categorical data based on diffusion models with a focus on high-quality sample generation, and propose sampled-based evaluation methods.
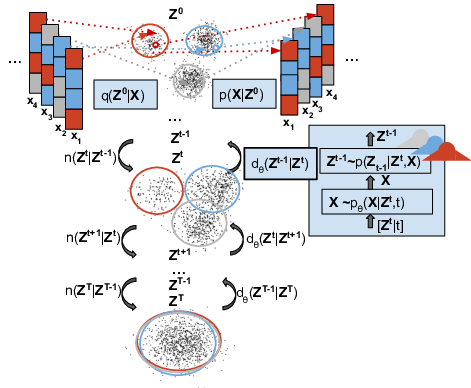
Sphere packing
To map the data to the continuous space, we use a a sphere packing algorithm to set a flexible and fixed encoding.
Idea: Solve a sphere packing problem -> Fits K well-separated balls in a d-dimensional real space: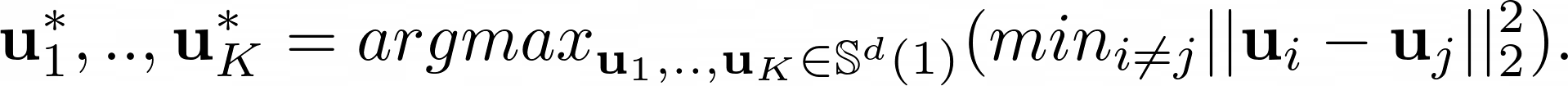
We can then use the solution to this problem to set the mean and variance of an encoding distribution conditioned on the category: where is derived from the min distance between .
| Argmax encoding. | Learned encoding. | Sphere packing encoding (ours). |
|---|---|---|
 | 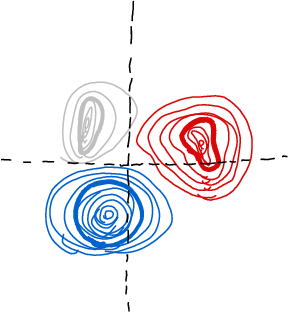 | 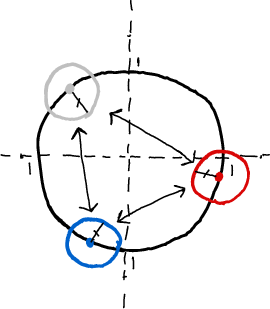 |
| 3 dimensions are needed to model 3 categories. | 2 dimensions can model 3 categories. | 2 dimensions can model 3 categories. |
Parameterizing the denoising step
This parameterization induces a structure on the targeted distribution, which enables us to design a task-cognizant Gaussian Mixtures denoising function:
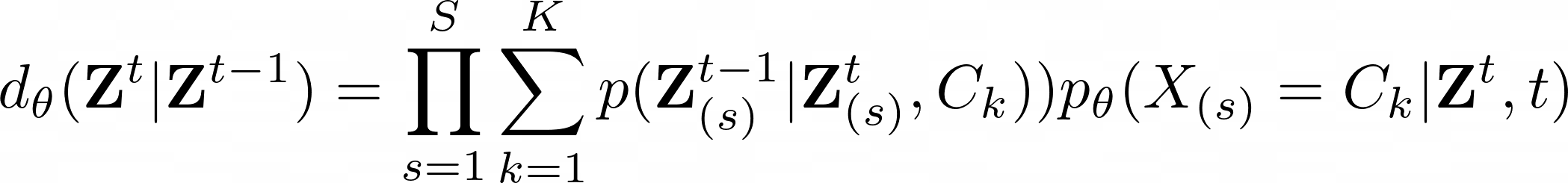
where is the -representation of . (). We can obtain a closed-from expression for the conditional ; it's a MV Gaussian with fixed paramters. Hence we only have to learn the mixture weights to learn the denoising step.
Team
Citation
This project was published in AAAI 2023.
@inproceedings{{regol2023,
title = {Diffusing Gaussian Mixtures for Generating Categorical Data},
author={Regol, Florence and Coates, Mark},
booktitle = {Proc. AAAI Conf. on Artificial Intelligence},
year = {2023}