Early-exit Dynamic Neural Network
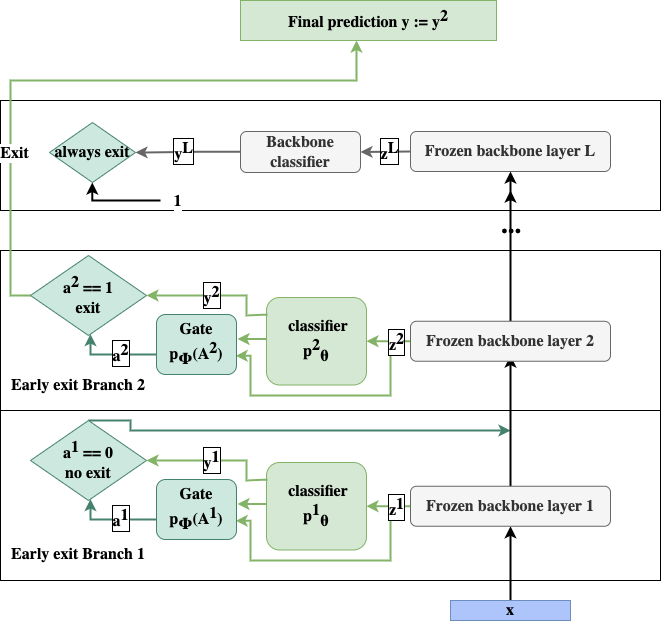
In this project we design a universal early-exit framework that can be attached on any backbone network to reduce inference cost by early exiting canonical (simple) samples.
Contribution
Early-exit networks have been studied for a few years. Initial works used fixed thresholds on confidence metrics to infer the difficulty of a sample and decide whether it could be exited earlier or not. Later work has treated the problem of exiting as a learnable task which could be described as a meta-learning problem. This made training significantly harder and those work therefore relied on a multi-phase top-down approach for training: the deepest classifier is trained then it is frozen when the deepest gate is trained, then the full layer is frozen and training moves to the previous layer.
Proceeding in a top-down approach creates a mismatch between train and test data. To address this we cast the problem as a bi-level optimization problem where classifiers are only trained with samples that have not been exited earlier. By training classifiers and gates alternately, each component adapts to the behaviour of the other.
While our method was developed on the token-to-token vision transformer (T2T-VIT), it can be adapted to any backbone. Our training approach allowed us to beat SotA early-exit architectures.