Multi-label Text Classification in Low Annotation Settings
Abstract
Multi-label text classification (MLTC) is the task of assigning multiple labels to a given text, and has a wide range of application domains. Most existing approaches require an enormous amount of annotated data to learn a classifier and/or a set of well-defined constraints on the label space struc- ture, such as hierarchical relations which may be complicated to provide as the number of labels increases. In this paper, we study the MLTC problem in annotation-free and scarce-annotation set- tings in which the magnitude of available supervision signals is linear to the number of labels. Our method follows three steps, (1) mapping input text into a set of preliminary label likelihoods by natu- ral language inference using a pre-trained language model, (2) calculating a signed label dependency graph by label descriptions, and (3) updating the preliminary label likelihoods with message passing along the label dependency graph, driven with a collective loss function that injects the information of expected label frequency and average multi-label cardinality of predictions. The experiments show that the proposed framework achieves effective performance under low supervision settings with almost imperceptible computational and memory overheads added to the usage of pre-trained language model outperforming its initial performance by 70% in terms of example-based F1 score.
Forming the Graph
We build a label dependency graph by drawing positive edges between labels who's token embeddings are similar according to a Cosine Similarity metric and negative edges between labels who's token embeddings are different according to the same metric. This graph will remain the same for each inference over the same label set. At each inference, however, we embed at each label node the entailment probability (positive classification) and contradiction probability (negative classification) of the corresponding label. These probabilities are calculated by a pre-trained language model. Thus, we now have our input graph for a message passing neural network architecture.
The Model
The model is a message passing graph neural network in which entailment-probability node embeddings (positive classification label probabilities) are updated at each layer using the entailment probabilities of positively-edged neighbors and the contradiction probabilities of the negatively-edged neighbors. This follows the intuition that "a friend of a friend is my friend" and "an enemy of my enemy is my friend", the analogy being that if two labels are considered similar and one has a high entailment probability then the other should as well (and similarly if a pair of labels are very different and one has high entailment the other should have high contradiction). See the diagram below for a toy example.
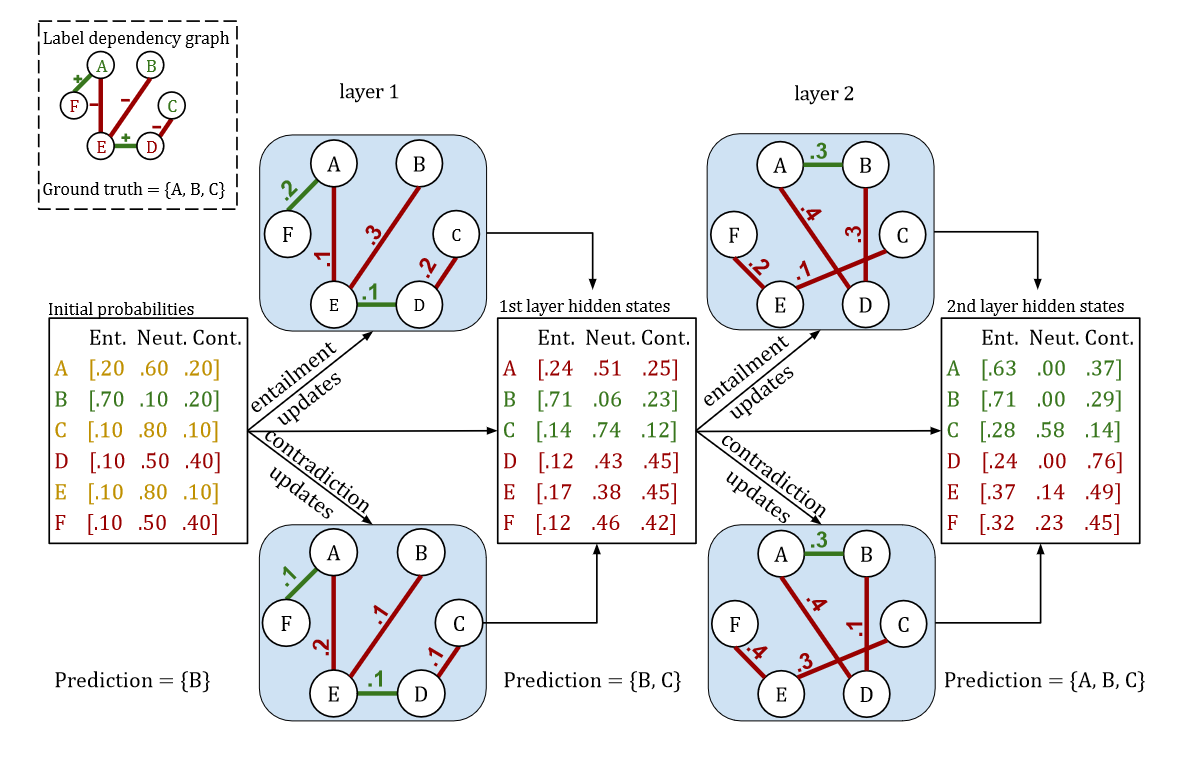
The Collective Loss Function
In many real-world settings, obtaining a large annotated corpus of text samples for supervised training is inaccessable due to the cost associated. Thus, we design a loss function that can be calculated without categorical labels. The loss function has four components:
- By definition entailment and contradiction are mutually exclusive events for each sample and each label. Therefore,
the sum of the two cannot be greater than one, and as the sum becomes closer to zero, the neutral probability
(hesitation to make a decision on the presence or absence of the label for a given sample) increases. Since hesitancy
is undesirable, we penalize the deviation of their summation from 1
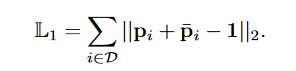
- For a specific training set, the classification decisions on training samples can impact each other. For example, a rare
label may have very low entailment probability for all samples. Assuming the training data are representative, the
samples to tag with that label can be selected by taking into account the expected observation probability. To ensure
this, we penalize the difference between observed and expected probability for each label over training instances

- It would be undesirable for some samples to have very high subset cardinality while others have zero. Therefore, we
penalize the deviation from average subset cardinality for each sample
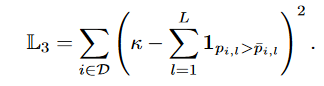
- There may be cases where a small amount of annotated data is available. In these cases, the following supervised loss term can be included.

The final loss function is a weighted sum of the previously outlined components. Loss weights are a hyperparameter to be tuned.
Team
Citation
This project was published in CoLLAs 2023.
@inproceedings{BNCL,
author = {Muberra Ozmen and Joseph Cotnareanu and Mark Coates},
booktitle={Second Conference on Lifelong Learning Agents (CoLLAs)},
title = {Substituting Data Annotation with Balanced Updates and Collective Loss in Multi-Label Text},
year = {2023}
}